
thrift的IDL,相当于一个钥匙。而thrift传输过程,相当于从两个房间之间的传输数据。
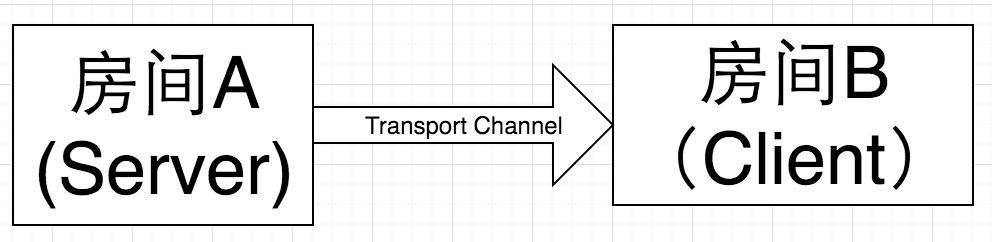
因为Thrift采用了C/S模型,不支持双向通信:client只能远程调用server端的RPC接口,但client端则没有RPC供server端调用,这意味着,client端能够主动与server端通信,但server端不能主动与client端通信而只能被动地对client端的请求作出应答。所以把上图中的箭头,画为单向箭头更为直观)基于上图,Thrift的IDL文件的作用可以描述为,从房间A要传递一批数据给房间B,把数据装在箱子里,锁上锁,然后通过Transport Channel把带锁的箱子给房间B,而Thrift IDL就是一套锁跟钥匙。房间A跟房间B都有同样的一个thrift IDL文件,有了这个文件就可以生成序列化跟反序列化的代码,就像锁跟钥匙一样。而一旦没有了Thrift IDL文件,房间A无法将数据序列化好锁紧箱子,房间B没有钥匙打开用箱子锁好传输过来的数据。因此,IDL文件的作用就在此。
为什么要用Thrift序列化, 不用纯文本的协议
我能想到的用thrift提供的thrift binary protocol而不用json、xml等纯文本序列化协议的几个好处如下:
- 序列化后的体积小, 省流量
- 序列化、反序列化的速度更快,提高性能
- 兼容性好,一些接口,涉及多种语言的int32、int64等等跟语言、机器、平台有关, 用纯文本可能有兼容性的问题
- 结合thrift transport技术,可以RPC精准地传递对象,而纯文本协议大多只能传递数据,而不能完完全全传递对象
关于以上几点我个人认为的好处,下面作一下简单解答
序列化后的体积小, 省流量
给出测试的IDL Services_A.thrift内容如下,定义了一些数据格式,这个结构体数据复杂度一般,有list、也有list对象、也有一些基本的struct等等。
namespace php Services.test.Anamespace java Services.tets.Astruct student{ 1:required string studentName, #学生姓名 2:required string sex, #性别 3:required i64 age, #学生年龄}struct banji{ 1:required string banjiName, #班级名称 2:required list allStudents, #所有学生}struct school { 1:required string schoolName, 2:required i64 age, 3:required list zhuanye, #所有专业 4:required list allBanji, #所有班级} 分别把Services_A.thrift 序列化为json、跟thrift.bin文件,序列化到文件中。对比文件大小。
这里用php写了一个例子, 代码如下:
registerNamespace('Thrift', __DIR__);$loader->registerNamespace('Services', __DIR__);$loader->registerDefinition('Services', __DIR__);$loader->register();require "Types.php";$school = [];$school['schoolName'] = "hahhaha";$school['age'] = 60;$school['zhuanye'] = [ '专业1', '专业2', '专业3',];$nameArr = ["张三", "李四", "王五", "王菲", "张韶涵", "王祖贤", "范冰冰", "新垣结衣", "詹姆斯", "诺维茨基"];$sexArr = ["男", "女"];$allBanji = [];for($i = 0; $i < 1000; $i ++){ $banji = []; $banji['banjiName'] = "计算机" + $i + "班"; for($j = 0; $j < 1000; $j ++) { $banji['allStudents'][] = new student( [ 'studentName' => $nameArr[rand(0, count($nameArr) - 1)], 'sex' => $sexArr[rand(0, count($sexArr) - 1)], 'age' => rand(0, 6) + 18, ] ); } $allBanji[] = new banji($banji);}$school['allBanji'] = $allBanji;$sc = new school($school);$str = json_encode($school);file_put_contents("/tmp/json_1", $str);$transport = new TBufferedTransport(new TPhpStreamMy(null, '/tmp/thrift_1.bin'), 1024, 1024);$sc->write(new TBinaryProtocol($transport, true, true)); 最终的结果, json文件跟thrift binary文件大小如下图:

thrift binary file是json文件大小的 0.63。为什么文件小这么多,我认为有以下几个原因,① json是文本的,而thrift是二进制的,文本文件跟二进制文件的区别,可以参考我的另一篇文章, 。② thrift序列化过程中,由于IDL在client、servo端都有一套,所以没有传输一些字段比如field name等等,只需要传递field id, 这样也是一些节省字节的方法。另外,提醒一下,序列化跟压缩不是一回事,比如上面的文件压缩为xz看看大小如下图:
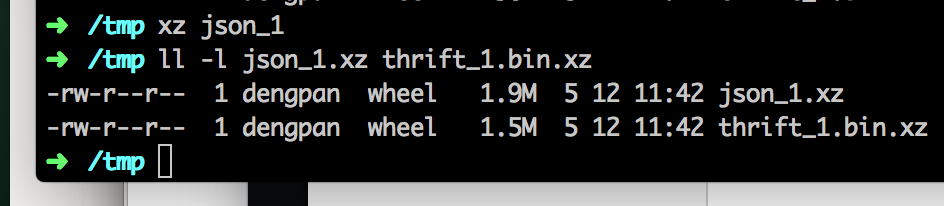
压缩后体积变为原来的3.3%、4.4%。可以先序列化再压缩传输,压缩的compress-level要指定合理,不然压缩跟解压缩占据系统资源而且耗时大。
序列化、反序列化的速度更快,提高性能
下面给出一个序列化反序列化测试
分别用① java Thrift binary protocol跟java fastjson库去序列以上对应格式为json, ②用C++ Thrift binary protocol与c++ jsoncpp序列化,对比速度,
java 测试代码如下:
public class ThriftDataWrite3 { private static final Random sRandom = new Random(); public static void main(String[] args) throws IOException, TException{ //构造school对象 String[] nameArr = {"张三", "李四", "王五", "赵6", "王祖贤", "赵敏", "漩涡鸣人", "诺维茨基", "邓肯", "克莱尔丹尼斯", "长门", "弥彦", "威少"}; int nameArrLength = nameArr.length; school sc = new school(); sc.setSchoolName("哈哈哈哈哈哈"); sc.setAge(12); List l = new ArrayList<>(); for (int i = 0; i < 100; i++) { l.add("专业" + i); } sc.setZhuanye(l); List allBanji = new ArrayList (); for (int i = 0; i < 1000; i++) { banji bj = new banji(); bj.setBanjiName("班级" + i); List allStuents = new ArrayList (); for (int j = 0; j < 1000; j ++) { allStuents.add( new student( nameArr[sRandom.nextInt(nameArrLength)], ((sRandom.nextInt(2) == 0) ? "男" : "女"), (sRandom.nextInt(10) + 18) ) ); } bj.setAllStudents(allStuents); allBanji.add(bj); } sc.setAllBanji(allBanji); //①序列化为thrift binary protocol final long startTime = System.currentTimeMillis(); TSerializer serializer = new TSerializer(new TBinaryProtocol.Factory()); for (int i = 0; i < 200; i++) { byte[] bytes = serializer.serialize(sc); //serializer.toString(sc); } final long endTime = System.currentTimeMillis(); System.out.println("thrift序列化200次时间为" + (endTime - startTime) + "ms"); //②序列化为json final long endTime7 = System.currentTimeMillis(); for (int i = 0; i < 200; i++) { JSON.toJSONString(sc); } final long endTime2 = System.currentTimeMillis(); System.out.println("json序列化200次时间为" + (endTime2 - endTime7) + "ms"); //准备待序列化的数据 byte[] bytes = serializer.serialize(sc); String jsonStr = JSON.toJSONString(sc); //③反序列thrift binary data final long endTime3 = System.currentTimeMillis(); TDeserializer tDeserializer = new TDeserializer(); for (int i = 0; i < 200; i++) { school sc1 = new school(); tDeserializer.deserialize(sc1, bytes);// System.out.println(sc1.toString()); } final long endTime4 = System.currentTimeMillis(); System.out.println("thrift反序列化200次时间为" + (endTime4 - endTime3) + "ms"); //④反序列化json final long endTime5 = System.currentTimeMillis(); for (int i = 0; i < 200; i++) { JSON.parseObject(jsonStr, sc.getClass());// System.out.println(JSON.parseObject(jsonStr, sc.getClass()).toString()); } final long endTime6 = System.currentTimeMillis(); System.out.println("json反序列化200次时间为" + (endTime6 - endTime5) + "ms"); }} java的序列化thrift、json,反序列化thrift跟json的结果为:
thrift序列化200次时间为82482ms
json序列化200次时间为167954ms thrift反序列化200次时间为42919ms json反序列化200次时间为207896ms其中可以看出java中thrift的序列化速度是fastjson 序列化json的2倍多,thrift反序列化的速度是fastjson反序列化json的接近5倍。
兼容性好
Thrift Types定义了一些基本的Base Type,分别在源代码各个语言中都有一一映射。但是每个语言中,不是所有的定义的类型都支持,Thrift的一些绝大多数语言都支持的base Type有void、bool、i16、i32、i64、double、string。然后thrift通过一一映射,将IDL里面的base Type与各种编程语言里面做了对应,这样可以保证兼容性。而且不会存在java提供的一个接口,一个json字段是i64的,到了C++调用http接口的时候,拿int去取这个字段,丢失了数字的高位。这种情况在跨语言调用,由于每个语言的int、long、short的位数与范围都不同,开发者涉及多语言需要对每个语言的类型范围、位数很清楚才可以避免这样的极端情况的丢失数据,而用了Thrift就不用担心了,它已经帮我们映射好了一些基准类型。后面的thrift code generator也是生成基于TBase类型的对象,用到的也都是thrift base types。关于thrift base type可以参考官方文档: 。具体的每个语言支持哪些Types定义,可以看源代码,比如thrift-src中,看到lib/rb/ext/thrift_native.c 中TType constants相关的为:
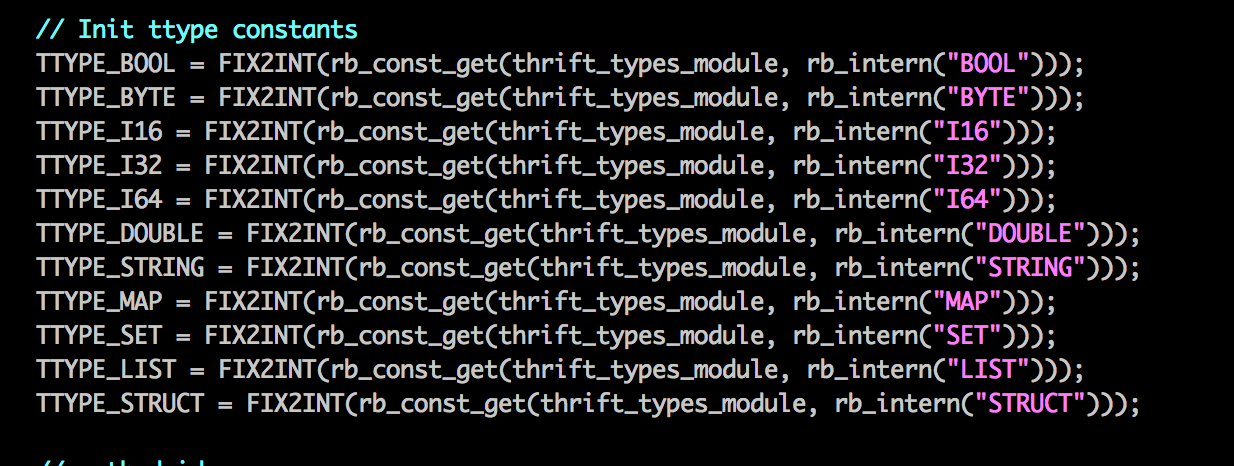
看到thrift跟ruby的类型支持情况,没看到binary, 说明ruby不支持binary类型。c++支持thrift的binary类型。其实基准类型,已经足够使用了,建议不要使用不属于i16、i32、i64、double、string、list、map之外的,非通用的TType,不然可能没事找事,碰到一些兼容问题。
1.4可传递对象
由于IDL的存在,可以在IDL里面定义一些表示层级关系,数据结构,把我们要传递的对象,翻译成IDL里面的struct, 然后再把IDL编译成对应文件,这样就可以传递对象了。json等文本协议,会丢失部分信息。比如php里面$a =[“name” => 123], json_encode后,跟 $a= new stdClass();$a->name = 123; json_encode之后,是一样的。一个是数组,一个是对象。类似的这种序列化中类型丢失或者改变的,其实还有其他的例子。要我们小心的去使用。(可能这个例子举得并不充分,因为php里面数组太灵活了,可以干绝大多数事情)。而Thrift,只要我们定义好IDL,就可以放心的去传递对象了。
二、序列化方法
任何一个Struct,Thrift code generator都为它生成了一个对应的class,该类都包含write和read方法,write就是serialie过程, read方法就是unserialize过程。由于Thrift是连带Client调用Service的代码整套生成的,因此想单独拿Thrift序列化一个对象官方没给什么例子,不过各种语言把struct序列化为binary的方法大同小异。我这里研究了下各种语言怎么把对象单独序列化为string,这里一并贴出来。
① C++ 序列thrift对象为string
boost::shared_ptr<TMemoryBuffer> buffer(new TMemoryBuffer());
boost::shared_ptr<TBinaryProtocol> binaryProtcol(new TBinaryProtocol(buffer));youThriftObj.write((binaryProtcol.get()));
buffer->getBufferAsString();② java序列化thrift对象为string
TSerializer serializer = new TSerializer(new TBinaryProtocol.Factory());
serializer.toString(bb); //就是序列后之后的string③ php序列化thrift对象为string
$memBuffer = new \Thrift\Transport\TMemoryBuffer();
$protocol = new TBinaryProtocol($memBuffer); $bbb->write($protocol); $str = $memBuffer->getBuffer();④ php序列化thrift对象到File
由于php中,没有TFileTransport, 因此改写了一下TPhpStream, 改成TPhpStreamMy,这样可以比较方便序列化到文件跟从文件中反序列化,这里也一并给出,。放到php Thrift lib的Thrift/Transport/TPhpStreamMy.php位置。
序列化thrift对象到file
$transport = new TBufferedTransport(new TPhpStreamMy(null, ‘your-thrift-binary-file-path’), 1024, 1024);
$yourThriftObj->write(new TBinaryProtocol($transport, true, true));从文件中读取thrift对象
$transport = new TBufferedTransport(new TPhpStreamMy(‘your-thrift-binary-file-path’, null), 1024, 1024);
$yourThriftObj->read(new TBinaryProtocol($transport));其他语言的thrift序列化过程,也是类似步骤。
三、反序列化方法
反序列化方法跟序列化方法步骤类似,主要是把write操作改为read操作即可,下面给出一些语言的反序列化方法:
① C++ 反序列string为Object
boost::shared_ptr<TMemoryBuffer> buffer(new TMemoryBuffer());
boost::shared_ptr<TBinaryProtocol> binaryProtcol(new TBinaryProtocol(buffer)); buffer->resetBuffer((uint8_t*)str.data(), str.length()); //str为thrift对象序列化之后的string yourThriftObj.read(binaryProtcol.get());② java反序列byte[]为Object
TDeserializer tDeserializer = new TDeserializer();
tDeserializer.deserialize(yourThriftObj, bytes); //bytes等于thrift对象序列化之后的byte[]或者
TTransport transport = new TIOStreamTransport(ByteArrayInputStream);
TBinaryProtocol tp = new TBinaryProtocol(transport); try { yourThriftObj.read(tp); System.out.println("反序列化后的对象:" + yourThriftObj.toString()); } catch (TException e) { e.printStackTrace(); }③ php反序列化string为Object
$memBuffer = new \Thrift\Transport\TMemoryBuffer($str); //str为thrift对象序列化之后的string
$protocol = new TBinaryProtocol($memBuffer); $yourThriftObj->read($protocol);其他语言的thrift反序列化过程,也是类似步骤。